Critiqued Fan-In
A multi-agent synthesis pattern with external rubric calibration.
The pattern shape that emerged from the
newsagentsystem, abstracted from
its news-monitoring instantiation. Reusable wherever multi-domain LLM
synthesis needs sustained quality discipline.
Intent
Produce a single calibrated artefact from multiple domain-specialist agents
in a way that (a) preserves depth in each domain, (b) forces deep synthesis
across domains, (c) detects when the synthesis is shallow or self-flattering,
and (d) keeps the discipline auditable rather than tacit.
Also Known As
- Specialist – Synthesizer – Critic
- Externally-Audited Iterative Synthesis
- Calibrated Fan-In
Context
You are building an LLM-based system that:
- Draws on multiple disjoint domains (legal/political/economic; security/trade; clinical/financial; legal/technical; etc.).
- Produces synthesis artefacts, not just retrieval results — the consumer wants a fused take, not a list of facts.
- Runs repeatedly over time, so artefact-to-artefact quality variance matters and silent regressions are expensive.
- Has tool access available (search, retrieval, code execution) for fact-gathering, but you want fact-gathering and fact-fusion to be separate concerns.
- Will be read or acted on by humans who need to know which claims are load-bearing and which are speculative.
This pattern is most useful when single-pass single-agent synthesis produces results that look good (LLMs are fluent) but audit poorly — restating sources, hedging on the hard claims, mistaking paraphrase for synthesis.
Problem
LLM-based synthesis has four endemic failure modes that compound when stacked naively:
- Single-pass shallowness. Asking one agent to “produce a deep analysis” yields a fluent surface read. The agent has no mechanism to deepen across iterations or notice what it has missed.
- Generalist dilution. A single agent asked to cover multiple domains either runs out of context for each domain or drops to lowest-common-denominator framing.
- Self-scoring inflation. When an LLM rates its own output (“on a scale of 1–10, how insightful is your analysis?”), it is systematically optimistic by ~2–3 points. Self-scored hill-climbing therefore plateaus invisibly — the model relabels and reframes without producing new claims, then certifies the rebranding as progress.
- Cross-run contradictions. Run-to-run, the same agent will produce mutually inconsistent facts (one run: “leader X assassinated”; next run: “leader X promoted”) without any mechanism flagging the contradiction. Downstream consumers cannot tell which is load-bearing.
The pattern resolves these by separating roles, formalising rubrics, and forcing external critique.
Forces
| Force | Tension |
|---|---|
| Depth ↔ breadth | A single agent covering many domains loses depth; many specialised agents lose synthesis. |
| Independence ↔ coordination | Specialists must run independently to preserve domain fidelity; their outputs must coordinate at fusion. |
| Iteration ↔ cost | More iterations improve depth but multiply latency and token cost. |
| Self-critique ↔ external critique | Self-critique is cheap and scales but is biased; external critique adds an agent but breaks the optimism. |
| Generality ↔ specificity | The pattern must be reusable across domains; the rubrics must be specific enough to score against. |
| Rigour ↔ velocity | A heavyweight discipline produces better artefacts but slows the pipeline; teams will skip steps under pressure. |
| Prompt agility ↔ code stability | Prompts evolve weekly; code shouldn’t churn at the same rate. |
Solution
Three generic roles, composed as a graph: a fan-out of independent Specialists into a Synthesizer (Orchestrator) into an Evaluator (Critic).
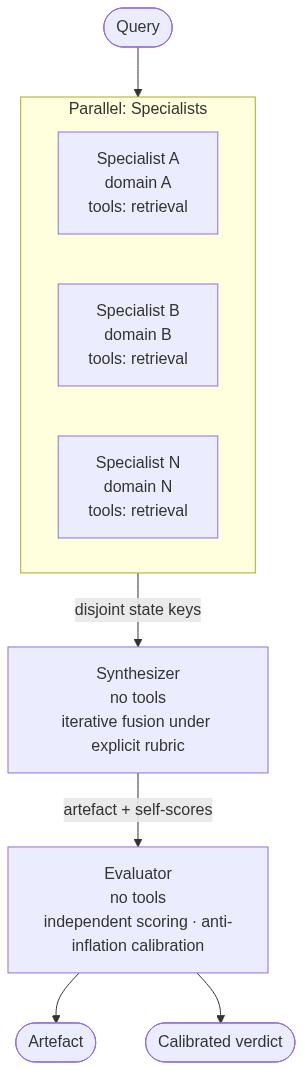
Each role has a single responsibility, communicates through named state keys rather than function arguments, and is instructed by an externalised prompt that can be edited without touching the wiring code.
The synthesis uses explicit scoring rubrics with two opposing objectives — one to maximise, one to minimise — applied at every iteration. Hill-climb thresholds (Δ on each objective) gate iteration-to-iteration progress. The Evaluator independently re-scores using the same rubrics with anti-inflation calibration anchors.
A fact-stability audit runs before publication: claims that contradict across upstream specialists are flagged with confidence tiers, and LOW-confidence claims are firewalled from load-bearing inferences.
Detailed Solution
Role 1 — Specialist
Purpose: produce structured facts and self-audited gaps for a single domain.
Responsibilities
– Owns a single domain (e.g., trade policy, geopolitics, clinical evidence, legal precedent).
– Has access to relevant tools (search, retrieval, structured-data APIs).
– Produces a structured brief at multiple layers (e.g., MACRO / MESO / MICRO).
– Self-audits: explicitly enumerates coverage gaps (parties or instruments expected but missing) and latent undercurrents (non-obvious second-order links).
– Attaches confidence tiers (HIGH / MEDIUM / LOW) to load-bearing factual claims, especially those subject to cross-run contradiction (leadership status, casualty counts, operational state).
– Writes its output to a dedicated state key, never overwriting another specialist’s namespace.
Anti-patterns
– A specialist that quietly produces a “generalist” view when its domain is sparse — silence about a missing fact is more useful than synthetic filler.
– A specialist that omits the coverage-gap audit because it found nothing — the audit is itself a signal.
Role 2 — Synthesizer (Orchestrator)
Purpose: fuse specialist outputs into a single artefact, iteratively, under explicit rubric pressure.
Responsibilities
– Has no tools. Re-research would invite duplicate work and contradict the graph’s separation of concerns.
– Reads upstream state keys via template substitution.
– Runs N iterations (typically 3), each exploring multiple analytical layers and ending with a what I missed reflection.
– Self-scores each iteration on two opposing rubrics:
– J⁺ (maximize): insight density / depth — composed of sub-dimensions like causal-mechanism naming, cross-domain coupling, forward predictiveness, novelty against headline framing, source-anchoring.
– J⁻ (minimize): surface-restatement penalty — composed of sub-dimensions like paraphrase ratio, fact-recombination-only, headline framing reuse, hedging without commitment, citation theatre.
– Enforces a hill-climb rule: each iteration must improve J⁺ by at least some threshold and reduce J⁻ by at least some threshold versus the prior iteration. If not, rewrite with a different aperture before publishing.
– Runs a fact-stability audit before publication: cross-checks entities mentioned in multiple upstream briefs, flags contradictions, attaches confidence tiers, applies a resolution rule (LOW-confidence facts cannot be load-bearing for analytical claims).
Anti-patterns
– Synthesizer with tools: it will start re-researching instead of synthesizing, and the iterations will diverge from the upstream briefs.
– Synthesizer without explicit rubrics: “deeper” becomes hand-wavy and iterations plateau without anyone noticing.
Role 3 — Evaluator (Critic)
Purpose: independently grade the synthesizer’s self-scores with explicit anti-inflation discipline.
Responsibilities
– Has no tools. Pure evaluation, no re-research.
– Reads both the upstream specialist briefs and the synthesizer’s output, so it can verify source-anchoring (claims must trace to specialist facts).
– Applies the same rubrics as the synthesizer, but with anti-inflation calibration anchors: explicit guidance about what a 10/10 actually means (paradigm-shifting, not just well-written), and a stated prior that the synthesizer’s self-scores are over-graded by 2–3 points.
– Produces a structured grading output: per-iteration calibrated scores, per-dimension justifications where it diverges from the synthesizer’s self-score, inflation diagnosis, concrete quoted passages that exhibit restatement or hedging or unanchored speculation, and a recalibrated hill-climb verdict.
– Provides a one-line recommendation for the next run.
Anti-patterns
– Evaluator using the same model as the synthesizer with no calibration anchors: it will rubber-stamp.
– Evaluator without access to the upstream briefs: cannot verify source-anchoring, becomes a stylistic critic only.
– Evaluator scoring without quoted evidence: produces opinion, not audit.
Communication and state
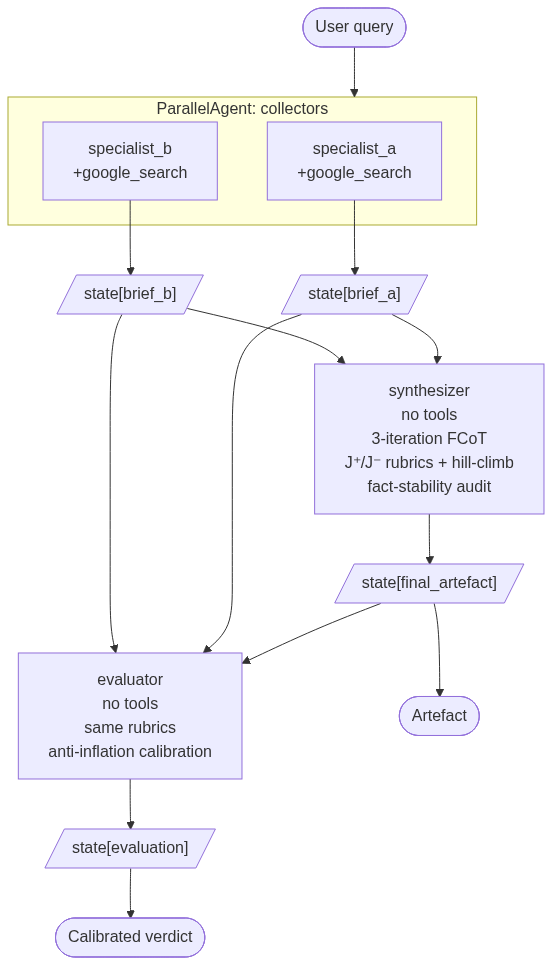
All inter-role communication happens through named, disjoint state keys. No role passes function arguments to another; every dependency is a state-key read.
| Producer | State key |
|---|---|
| Specialist A | state[brief_a] |
| Specialist B | state[brief_b] |
| Specialist N | state[brief_n] |
| Synthesizer | state[final_artefact] |
| Evaluator | state[evaluation] |
This makes the graph fully composable: any specialist can be added or removed by editing the fan-out stage and the synthesizer’s template, without touching the agent code paths.
Iteration discipline and hill-climbing
Each synthesizer iteration is a structured pass with these components:
- Layered analysis — macro / meso / micro (or any domain-appropriate set of zoom levels).
- What I missed — explicit enumeration of 3–5 gaps in this iteration’s coverage.
- Score — J⁺ and J⁻ with per-dimension breakdown.
- Hill-climb check — vs. prior iteration; rewrite if thresholds unmet.
The structural insight: iteration N must address the gaps surfaced by iteration N−1’s what-I-missed section. This forces aperture changes between iterations rather than mere depth at the same aperture.
Externalised prompts
Each role’s prompt lives in a separate Markdown file, loaded at module import time. This keeps the prompt as artefact rather than as code-string:
project/
agents/
specialist_a.py # 25 lines: wiring only
specialist_b.py
synthesizer.py
evaluator.py
prompts/
specialist_a.md # full prompt
specialist_b.md
orchestrator.md
evaluator.md
The agent module loads the prompt via the language’s resource-loading idiom (e.g., importlib.resources in Python). A test asserts that the agent’s runtime instruction equals the on-disk file content, preventing silent re-inlining.
Benefits:
– Prompts are editable without touching code; git blame stays clean on the wiring.
– Prompts can be diffed and reviewed as documents.
– Rubric tuning becomes a Markdown PR, not a Python PR.
– Prompts can be deployed independently of code in environments that support hot-reload.
Diagram (concrete instantiation)
Consequences
Benefits
- Synthesis quality is auditable. The hill-climb trajectory is a number sequence, not a vibe.
- Self-scoring inflation is caught. The Evaluator routinely catches iterations where the Synthesizer relabelled iter-2 content as “iter-3 novelty” and certified the rebranding as progress.
- Domain depth is preserved. Each Specialist stays in scope; cross-cutting synthesis is the Synthesizer’s job, not its job.
- Cross-run consistency is enforced. Fact-stability audits surface contradictions and apply confidence tiers, so consumers know which claims to trust.
- Roles are modular. Specialists can be added or swapped without rewriting the Synthesizer; Evaluator can be swapped to a different model to reduce same-model bias.
- Prompt churn is decoupled from code churn. Externalised prompts mean a rubric-tuning PR doesn’t touch wiring code.
- The artefact is falsifiable. The Synthesizer’s iteration 3 includes explicit falsification triggers — observations that would invalidate the analysis. This is the discipline equivalent of a forecast confidence interval.
Liabilities
- Three stages = 3× minimum latency. A single specialist-synthesizer run is ~30s; adding the Evaluator can push wall-clock past 60s. Unsuitable for real-time interaction.
- Three stages = 3× cost. Each pass burns tokens at LLM rates; the Evaluator pass adds ~30% over a synthesizer-only design.
- Rubric design is hard. Bad rubrics produce false confidence. The dimensions must be operationalisable (each scoreable from the artefact alone) or the scoring degrades to vibes.
- Plateau detection requires the Evaluator. Without it, the Synthesizer’s claimed hill-climb is rarely the actual hill-climb. Cutting the Evaluator to save cost re-introduces the original problem.
- Same-model bias. If the Synthesizer and Evaluator share the same underlying model and weights, the Evaluator may share the Synthesizer’s blind spots. Mitigated by anti-inflation anchors but not eliminated. Best practice: pin the Evaluator to a different model when feasible.
- Cold-start cost on each rubric change. Calibrating the Evaluator’s anti-inflation anchors against a new rubric requires some manual tuning.
- The Specialists’ tool calls dominate the latency budget. If retrieval is slow, the parallel fan-out helps but does not eliminate the floor.
When NOT to apply
- Single-domain content, where there is no synthesis to fuse — just use one agent.
- High-frequency / low-latency systems where 60s wall-clock is unacceptable.
- Cost-sensitive deployments where 3× token cost is unjustified.
- One-off generation where iteration discipline is overkill — a single-pass agent suffices.
- Domains without scoring traction. If you can’t define a meaningful J⁺ / J⁻ rubric for the artefact, the hill-climb machinery cannot grip the synthesis and degrades to ceremony.
Implementation Notes
Choosing N iterations
Three is a practical default. The empirical pattern observed in the newsagent instantiation:
- Iter 1 → Iter 2: largest improvement; the synthesizer goes from surface description to coupled mechanisms.
- Iter 2 → Iter 3: smaller improvement, more inflation. The synthesizer is prone to relabel iter-2 content under a new header.
Two iterations under-deliver depth; four are usually wasted. The hill-climb rule lets you abort earlier if Δ thresholds are met sooner; this is the right escape valve.
Designing the rubrics
Good J⁺ / J⁻ dimensions are:
- Operationalisable — each one scoreable from the artefact text alone, without re-querying tools.
- Orthogonal — separate dimensions don’t trade off mechanically. If “depth” and “novelty” always move together, they are one dimension, not two.
- Anchored — each score level has a quoted example, not just an adjective.
A useful test: hand the rubric to a human who hasn’t read the artefact and ask them to score it. If two readers diverge by more than 1 point on most dimensions, the rubric is under-specified.
Anti-inflation calibration anchors
The Evaluator’s prompt should include explicit statements like:
- “A perfect 10 is reserved for paradigm-shifting analysis. Most competent output lands 6–8.“
- “Prior on the Synthesizer’s self-score: when it claims 10, the prior is over-grading by 2–3 points.“
Without these anchors, the Evaluator will be sympathetic to the Synthesizer’s framing and grade indistinguishably from self-scoring.
Confidence tiers
Three tiers (HIGH / MEDIUM / LOW) is enough granularity. Five or more tiers invite false precision; two collapse to “true / not-sure” and lose the firewall mechanism.
The resolution rule matters as much as the tiers: a LOW-confidence claim cannot be load-bearing for downstream inferences. The Synthesizer must downgrade the dependent claim or label it conditional. Without this rule, LOW-confidence claims propagate as if they were HIGH.
Test discipline
Three test categories to maintain:
- Wiring tests — agent name, tool list, state-key output. Catches structural drift.
- Prompt-content tests — assert that specific rubric tokens (e.g., “causal depth”, “hill-climb”) appear in each prompt. Catches silent prompt regressions where someone trims the rubric.
- Externalisation lock-in — assert that
agent.instruction == read_file(prompt.md). Catches re-inlining.
The lock-in test is the one most often skipped and most useful.
Known Uses
newsagent— geopolitical + tariff news monitoring (this codebase). Two specialists (geopolitical, tariff) withgoogle_search, one synthesizer running 3-iteration FCoT with J⁺ / J⁻ rubrics and fact-stability audit, one evaluator with anti-inflation calibration.- Clinical case review: specialists for radiology / pathology / labs / patient history, synthesizer for diagnostic synthesis, evaluator for clinical-rigour calibration.
- Investment memos: specialists for fundamentals / competitive landscape / macro / regulatory, synthesizer for thesis, evaluator for risk-attribution calibration.
- Legal-brief synthesis: specialists for case law / statutory / factual record, synthesizer for argument, evaluator for citation-rigour and precedent-applicability calibration.
- Threat intelligence: specialists for IoCs / TTPs / adversary profiles / asset exposure, synthesizer for risk narrative, evaluator for actionability calibration.
Variants
- Feedback-loop variant. After the Evaluator scores, route its one-line recommendation back to the Synthesizer for one more iteration. Useful when the artefact has high stakes; doubles latency.
- Specialist-of-specialists variant. A Specialist may itself be a sub-pipeline (e.g., a “legal” specialist that contains case-law and statutory sub-specialists). Recursive Critiqued Fan-In.
- Per-iteration evaluator variant. Evaluator runs after each Synthesizer iteration rather than only at the end. Higher cost; tighter feedback. Useful when iterations diverge widely in quality.
- Multi-model evaluator variant. Two Evaluators on different model families; their scores are averaged or their disagreements flagged. Strongest mitigation of same-model bias.
- Tool-using evaluator variant. Evaluator has limited tools to verify a Synthesizer claim against an external source. Risks scope creep; useful for high-stakes factual claims.
Anti-patterns
- Rubber-stamp Critic. Evaluator with no anti-inflation anchors, on the same model as the Synthesizer. Produces scores that mirror the Synthesizer’s self-scores and adds latency without adding signal.
- Rubric-less Synthesis. Synthesizer told to “iterate and improve” without a scoring discipline. Iterations plateau into recombination at iter 2.
- No fact-stability audit. Cross-run contradictions ship unflagged. Consumers cannot tell which is the load-bearing claim.
- Generalist Specialist. A “Specialist” whose scope is broad enough to overlap with another’s. Produces duplicate coverage that the Synthesizer must deduplicate, wasting iterations.
- Prompt as code-string. Prompts inlined as triple-quoted strings in Python. Editing requires code PRs; reviewers can’t focus on prompt content; rubric tweaks pollute git blame.
- Hill-climb without thresholds. “Each iteration should be deeper” without a numeric Δ floor — produces movement without measurable progress.
Related Patterns
- Map-Reduce — Critiqued Fan-In is a refinement where the reduce step is iterative, scored, and externally audited.
- Pipeline — Critiqued Fan-In is a pipeline whose middle stage is internally iterative.
- LLM-as-Judge — Critiqued Fan-In uses this technique specifically for scoring rubric application, paired with anti-inflation calibration to defuse its known bias.
- Constitutional AI / RLAIF — Critiqued Fan-In is a runtime, per-artefact version of the same impulse: separate the producer from the critic. Constitutional AI bakes the critic into training; Critiqued Fan-In runs it at inference.
- Self-Refine — Single-agent self-critique. Critiqued Fan-In separates self-critique (Synthesizer’s iteration what-I-missed) from external critique (Evaluator) because they catch different classes of failure.
- Multi-Agent Debate — Adversarial multi-agent reasoning. Critiqued Fan-In differs in that there is no debate: the Specialists are non-overlapping, the Synthesizer is sole-author, and the Evaluator is non-participating critic.
Summary
Critiqued Fan-In is a three-role multi-agent pattern: Specialists fan out by domain, a Synthesizer fuses through iterative scoring, and an Evaluator independently grades with anti-inflation discipline. Its central insight is that LLM synthesis quality is recoverable through explicit rubrics and external critique — but only if those are operationalised structurally, not aspirationally. The pattern’s cost is latency and tokens; its return is auditable depth, cross-run consistency, and a falsifiable artefact that survives review.
Appendix A — Worked Example: Investment Memo Synthesis
The simplest way to test whether a pattern is genuinely abstract is to apply
it to a domain it wasn’t designed for. Below: a full instantiation in equity
research, with concrete role decomposition, rubric adaptation, and prompt
sketches. The shape is identical to newsagent; almost everything else
shifts.
Context
- Team: equity-research desk at an investment firm.
- Artefact: weekly investment memo per candidate position — thesis + risks + position-sizing recommendation.
- Audience: investment committee, votes on positions during weekly review.
- Cadence: 5–15 memos per week across the team. Quality matters more than latency; a memo that takes 90 seconds to render is acceptable.
- Stakes: each memo, if accepted, drives a position whose size–weighted P&L compounds in the fund. Confirmation bias and tail-risk under-weighting are the dominant failure modes.
Role decomposition
Four specialists instead of two, each with primary-source access:
| Role | Domain scope | Primary tools |
|---|---|---|
fundamentals_agent |
Financials, unit economics, capital structure, management track record | EDGAR retrieval, earnings transcripts, internal model snapshot |
competitive_agent |
Market position, moat structure, competitor trajectory, customer concentration | Market-research APIs, web search, channel-check notes |
macro_agent |
Interest-rate path, sector cyclicals, currency exposure, commodity sensitivity | Bloomberg / FactSet feeds, economic calendars |
regulatory_agent |
Litigation docket, regulatory pipeline, antitrust risk, policy exposure | Court records, regulatory filings, policy-shop research |
Each writes to a dedicated state key (state[fundamentals_brief], etc.) with the same internal structure as newsagent specialists: MACRO/MESO/MICRO layering, COVERAGE GAPS, LATENT UNDERCURRENTS, confidence-tier-tagged claims.
| Role | Scope | State key |
|---|---|---|
thesis_synthesizer |
Fuses all four briefs into a thesis + position-sizing recommendation | state[memo] |
risk_calibrator |
External evaluator — grades the synthesizer with finance-specific anti-inflation calibration | state[evaluation] |
Rubric adaptation
This is the largest deliberate change from newsagent. The objectives swap entirely:
J⁺ — Thesis Sharpness (max)
| Dimension | 0 | 1 | 2 |
|---|---|---|---|
| Causal Mechanism | Narrative (“they should do well”) | Plausible link | Falsifiable mechanism connecting fundamentals → revaluation |
| Cross-Domain Coupling | Single specialist’s view | Linked but not mechanised | Explicit chain (e.g., regulatory ruling → competitive realignment → margin expansion) |
| Named Catalyst | None | Vague timeframe | Specific event with quarter/date and pre-committed sign |
| Non-Consensus | Consensus thesis | Slight contrarian lean | Differentiates from sell-side median with stated reason |
| Source-Anchored | Speculative | Loosely supported | Every step traceable to a specialist brief |
J⁻ — Confirmation-Bias / Pitch-Deck Penalty (min)
| Dimension | 0 | 1 | 2 |
|---|---|---|---|
| Cherry-Picking | Both confirming and disconfirming evidence cited | Disconfirming evidence acknowledged but discounted | Bull-case only |
| Hedge-Then-Recommend | Committed view, owns its risk | Some hedging | “But we still like it” after listing reasons not to |
| Narrative-Over-Numbers | Numbers carry the claim | Numbers support a narrative | Story carries the claim, numbers decorative |
| Anchoring to Current Price | Price-independent thesis | Some price reference | Thesis collapses if the stock is +/− 20% from here |
| Survivorship in Analogs | Both winning and losing analog cases cited | Mostly winning analogs | Only winning analogs (the “next Amazon” trap) |
The newsagent J⁻ minimises restatement; the investment-memo J⁻ minimises self-serving framing. The shape is identical: five 0–2 dimensions, sum 0–10, lower better.
Evaluator calibration anchors
The risk_calibrator prompt swaps the news-monitoring anti-inflation anchors for finance-specific ones:
“A J⁺ of 10/10 is reserved for memos that name a non-consensus catalyst, a falsifiable mechanism, and at least one cross-domain coupling. Most competent memos land 5–7.”
“Equity-research memos are systematically optimistic on management quality and systematically pessimistic about tail-risk recognition (analysts under-imagine adverse scenarios). Apply a +1 J⁻ discount on memos that conclude BUY without containing at least one specific disconfirming observation that would be considered material.”
“If the memo’s reasoning depends on the current stock price being a reference point, J⁻ Anchoring is at least 1, regardless of whether price is named.”
The two-layer optimism counter — LLM optimism plus analyst optimism — is unique to this domain. The newsagent evaluator only counters one.
Confidence-tier mapping
Source-type provenance, not source-count, is the right tier driver in finance:
| Tier | Sources |
|---|---|
| HIGH | Filed financials (10-K/10-Q), final court rulings, signed deal terms, official regulatory orders |
| MEDIUM | Sell-side consensus, management guidance, settled lawsuits without appeal, finalised regulatory comment periods |
| LOW | Management commentary on earnings calls, industry rumours, channel-check anecdotes, expert-network calls, unconfirmed press reports |
Resolution rule: A LOW-confidence claim cannot be load-bearing for a BUY/SELL conclusion. If the conclusion depends on a LOW-confidence input, either downgrade the conclusion to “WATCH” or label the recommendation explicitly conditional.
Falsification triggers (per memo)
The synthesizer must produce 2–3 named falsifiers, e.g.:
- “If next quarter’s gross margin contracts more than 80 bps, the operating-leverage thesis is wrong.”
- “If competitor X enters segment Y before our 18-month mark, the moat thesis is wrong.”
- “If regulation Z passes in its current form, the TAM revises down 30%+ and the position should be exited.”
These get tracked in a positions register post-publication. Falsifier-hit triggers a memo re-open, not a quiet quiet-mute.
What changes vs newsagent
| Aspect | newsagent |
Investment memos |
|---|---|---|
| Specialist count | 2 (geopolitical, tariff) | 4 (fundamentals, competitive, macro, regulatory) |
| Specialist tools | google_search |
Mixed: EDGAR, market-data APIs, legal/regulatory search, channel-check notes |
| Cadence | Daily / ad-hoc | Weekly per position; 5–15 per week per team |
| Failure mode J⁻ targets | Surface restatement of headlines | Confirmation bias / pitch-deck framing |
| Evaluator anti-inflation priors | One: LLM optimism | Two: LLM optimism plus analyst-thesis optimism |
| Confidence-tier driver | Source breadth | Source primacy (filed > guided > anecdotal) |
| Resolution-rule consequence | Downgrade analytical claim | Downgrade recommendation (BUY → WATCH) |
| Output consumer | Reader | Investment committee voting on capital allocation |
The role count doubles for specialists; the role kinds (Specialist / Synthesizer / Evaluator) stay at three. The pattern is unchanged; the instantiation expands.
Implementation sketch
investment_agent/
├── pyproject.toml
├── investment_agent/
│ ├── agents/
│ │ ├── fundamentals_agent.py
│ │ ├── competitive_agent.py
│ │ ├── macro_agent.py
│ │ ├── regulatory_agent.py
│ │ ├── thesis_synthesizer.py
│ │ └── risk_calibrator.py
│ ├── prompts/
│ │ ├── fundamentals.md
│ │ ├── competitive.md
│ │ ├── macro.md
│ │ ├── regulatory.md
│ │ ├── thesis.md # synthesizer
│ │ └── risk_calibrator.md # evaluator
│ ├── tools/
│ │ ├── edgar.py
│ │ ├── market_data.py
│ │ └── legal_search.py
│ ├── workflow.py
│ └── orchestrator.py
└── tests/
└── ... # same three test categories: wiring, prompt content, externalisation lock-in
A 6-line prompt sketch (synthesizer head)
What changes structurally is small; the J⁻ vocabulary is what carries the domain shift:
You are the lead PM authoring an investment memo for the weekly committee.
Four analysts have filed:
FUNDAMENTALS BRIEF: {fundamentals_brief}
COMPETITIVE BRIEF: {competitive_brief}
MACRO BRIEF: {macro_brief}
REGULATORY BRIEF: {regulatory_brief}
Synthesize using fractal chain-of-thought across three iterations. Each
iteration must address gaps from the prior iteration's WHAT I MISSED.
J⁺ — MAXIMIZE thesis sharpness (causal mechanism, cross-domain coupling,
named catalyst, non-consensus, source-anchoring).
J⁻ — MINIMIZE pitch-deck framing (cherry-picking, hedge-then-recommend,
narrative-over-numbers, price-anchoring, survivorship in analogs).
Hill-climb rule: ΔJ⁺ ≥ +1.5 and ΔJ⁻ ≤ −1 vs. prior iteration, else REWRITE.
Before publication run the fact-stability audit (HIGH/MEDIUM/LOW tiers on
every load-bearing claim). LOW-tier facts cannot anchor a BUY conclusion.
Produce: HEADLINE THESIS, RISK BUDGET, CATALYSTS, FALSIFIERS, SIZING.
The rest of the prompt mirrors orchestrator.md structurally — three iterations, what-I-missed reflections, scores per iteration, hill-climb thresholds, fact-stability audit, publication order. The dimensions of J⁺ and J⁻ change; the machinery does not.
Pattern-fit observations
- Specialist scope discipline matters more here. With four specialists, scope overlap is common (a regulatory ruling has macro consequences; a competitive shift affects fundamentals). The pattern’s response is the same: hard scope boundaries, with cross-cutting analysis owned solely by the synthesizer.
- The fact-stability audit becomes load-bearing. Management guidance (MEDIUM) often contradicts filed financials (HIGH); sell-side consensus (MEDIUM) often contradicts channel-check anecdotes (LOW). The audit is the mechanism that prevents the synthesizer from quietly resolving these in the bullish direction.
- The evaluator’s anti-inflation discipline does double duty. It fights both LLM self-grading optimism and analyst-thesis optimism. This is why the calibration anchors must be domain-specific. A generic anchor (“most memos land 6–8”) would miss the systematic finance-specific bias.
Domain-specific anti-patterns
- Specialist-as-pitch-deck. A
fundamentals_agentthat writes a brochure instead of a brief. The fix is the same as innewsagent: enforce the COVERAGE GAPS section, and grade specialists on whether they flag missing data rather than fill it. - Synthesizer-with-price-target-bias. A
thesis_synthesizerwhose internal prior is “thesis ends with a price target,” which then back-fits the analysis to the target. Counter: the synthesizer prompt should explicitly forbid starting with a target. - Evaluator-with-house-view-bias. A
risk_calibratorthat defers to the synthesizer because “the firm has long owned this.” Counter: pin the evaluator to a different model from the synthesizer, and seed the calibrator with the firm’s historical error patterns rather than current positions. - Missing devil’s-advocate. If the firm’s culture rewards conviction, the evaluator role gets undercut socially. Counter: codify the evaluator’s output as a required field on the memo template — no committee vote without a calibrated risk-call.
One-paragraph summary of the transfer
The Critiqued Fan-In pattern moves from news monitoring to investment-memo
production with role-renaming and rubric-substitution. The synthesis machinery
(three iterations, J⁺ maximisation and J⁻ minimisation, hill-climb thresholds,
fact-stability audit, externally-calibrated evaluator) stays identical. What
shifts is what J⁻ minimises (here: confirmation bias instead of restatement),
what calibration anchors the evaluator applies (here: two-layer optimism
counter instead of one), and what the resolution rule downgrades when a LOW-
confidence fact is load-bearing (here: a BUY recommendation instead of an
analytical claim). The pattern’s three-role architecture, state-key
communication, and externalised-prompt governance carry over without
modification. If the same code skeleton ships unchanged and only the
prompts/ directory rewrites, the transfer is successful.